
Let’s imagine you’re entering a coffee shop for the first time. As you step inside, you immediately anticipate seeing a counter where you can place your order, a menu board showcasing various coffee options, and a comfortable seat where you can relax and enjoy your drink. These expectations are built upon your schema for a typical coffee shop.
Your schema for a coffee shop represents a mental framework that aids in navigating and comprehending the environment. It encompasses your knowledge and assumptions regarding such establishments’ customary layout, services, and ambiance. This schema enables you to understand the situation swiftly and influences your actions. You instinctively know where to go to order, what menu choices to expect, and where to locate seating.
In this blog, we will discuss what is schema in database, database schema design, the tools and techniques for managing schema migrations, and version control to ensure smooth updates.
Let’s begin with the primary discussion about database schema.
Table Of Contents
- What Is Schema in Database?
- Importance and Purpose of a Database Schema
- Components of Database Schema
- Types of Database Schemas
- Database Schema Models
- Benefits of Database Schemas
- The Process of Creating a Database Schema
- The Steps Required To Create Database Schema
- Best Practices for Database Schema Design
- Steps in Database Schema Evolution and Maintenance
- Conclusion
- FAQ
What Is Schema in Database?
A database schema is responsible for defining the structure and organization of data within a relational database. It covers logical constraints like table names, fields, data types, and entity relationships.
Schemas can be represented as visual diagrams that represent the database architecture. This allows all users to apply the best data management practices when building or interacting with the database.
Data Modeling For Defining Database Schema
This process of designing a database schema is commonly referred to as data modeling.
Data models are crucial for stakeholders, including database users, administrators, and programmers.
For instance, they aid database administrators in managing normalization processes to prevent data duplication and ensure data integrity. Similarly, these models enable analysts to navigate the data structures for generating report templates and performing business analysis operations.
The visual diagrams generated from the schema are part of the database management system (DBMS) documentation users can access to understand how the database is structured. . , ensuring alignment and understanding among various stakeholders.
Importance and Purpose of a Database Schema
After discussing what is schema in a database, let’s understand the importance and purpose behind a database schema.
- The database schema facilitates the identification of tables and their fields.
- It outlines the connections and relationships between various tables within the database.
- The schema aids in recognizing and enforcing constraints within the system.
- It is a formal structure defined within the DBMS.
- The schema defines tables, fields, relationships, views, and indexes.
- Database schemas serve as a roadmap for organizing and structuring data within a database management system.
- Schemas ensure data consistency and integrity by specifying rules and relationships between entities.
- They guide developers and database administrators in the design and implementation process.
- Database admins can modify schemas as operational requirements change over time.
Components of Database Schema
As mentioned earlier, database schemas are a detailed roadmap to organizing and storing data within the database structure.
Understanding database schema design is essential for working with any database. This is especially important if you’re using the database as a component of a more extensive application, such as an eCommerce store.
Let’s discuss the various components of a database schema in detail to see how they relate and combine to facilitate database operations:
Table
The idea of tables lies at the core of a database schema.
It represents a structured collection of related data organized into rows and columns. Each table has a name and consists of one or more columns (fields) and rows (records) that store the actual data.
Column
Columns also referred to as fields or attributes, define the specific data types that can be stored in a table. Each column has a name, a data type (e.g., string, integer, date), and additional properties like length, precision, and constraints.
Index
Indexes are data structures designed to enhance the performance of database operations by facilitating rapid data access. They are created on one or more columns within a table and act as a pointer to the original row. Indexes speed up searches, sorting, and joining operations.
Constraint
Constraints establish rules or conditions that restrict the data that could be stored in a database. These constraints are critical to ensuring data integrity and consistency. A database schema can contain several constraints, including primary, unique, check, and foreign key constraints.
View
Views are virtual tables generated from the outcome of a query. They provide a unique perspective on presenting the data stored in one or more tables. Views are used to simplify complex queries, limit access to sensitive information, and offer customized representations to the columns in a database.
Trigger
Triggers are specialized stored procedures executed automatically in response to specific events or actions performed on the database. These procedures apply the application’s logic that uses the database for data storage and retrieval. Common examples of triggers include business rules, data validation, or special procedures that are executed when certain conditions are met.
Types of Database Schemas
Database schemas come in several flavors – each catering to specific requirements. Understanding these types is essential to what is schema in database. Let’s go through the details of the types of database schemas.
Relational Database Schemas
Relational database schemas adhere to the traditional relational model, which organizes data into tables with rows and columns. They involve defining tables, establishing relationships using primary and foreign keys, and enforcing integrity constraints. Relational database schemas exhibit the following characteristics:
Tabular Structure
Data is organized in tables, with each table representing an entity and each row representing a record or instance of that entity. Columns define the attributes or properties of the entity.
Relationships
Relationships between tables are established through primary keys and foreign keys. These relationships ensure data consistency and referential integrity and support efficient joins to retrieve related information.
Relational schemas often employ normalization techniques to minimize data redundancy and enhance data integrity. This involves breaking down tables into smaller components to eliminate duplication and improve data retrieval efficiency.
Object-Oriented Database Schemas
Object-oriented database schemas are designed to handle complex data structures by treating data as objects. They combine data and behavior, enabling features such as inheritance, encapsulation, and polymorphism.
Critical advantages of object-oriented database schemas include:
Complex Data Modeling
Object-oriented schemas provide a more natural way to model complex relationships and hierarchies than relational schemas. They can better represent real-world objects and more intuitively model their attributes and behaviors.
Reusability and Extensibility
Object-oriented schemas facilitate code reuse through inheritance, allowing objects to inherit attributes and behaviors from other objects. This promotes extensibility and modularity in application development.
Performance
Object-oriented databases can improve performance for certain applications, especially those involving complex queries and navigational access patterns.
Hierarchical Schema
The data is organized hierarchically in this schema as a tree, with parent-child relationships. Each record has a single parent, except for the root record. Hierarchical schemas excel at representing one-to-many relationships but can be less flexible for complex relationships.
Hierarchical schemas were widely used in early database systems, especially in mainframe environments. They were well-suited for applications with transparent and predictable data structures, such as file systems or organizational hierarchies. However, hierarchical schemas have certain limitations when representing intricate relationships and adapting to structural changes. As a result, they offer less flexibility compared to relational schemas.
Network Schema
Multiple Parent-Child Relationships
Unlike the hierarchical schema, a record in a network schema can have multiple parent nodes. This feature allows for the representation of many-to-many relationships between entities.
Pointers and Sets
The network schema utilizes pointers to establish connections and relationships between records. These pointers enable direct access to related records, facilitating efficient navigation within the database structure. Additionally, sets can be utilized to group related records.
Flexibility
The network schema offers a higher degree of flexibility compared to the hierarchical schema. It excels in representing complex relationships and provides improved accessibility to data. The network schema can handle interconnected data structures more efficiently, such as overlapping hierarchies or networks.
Database Schema Models
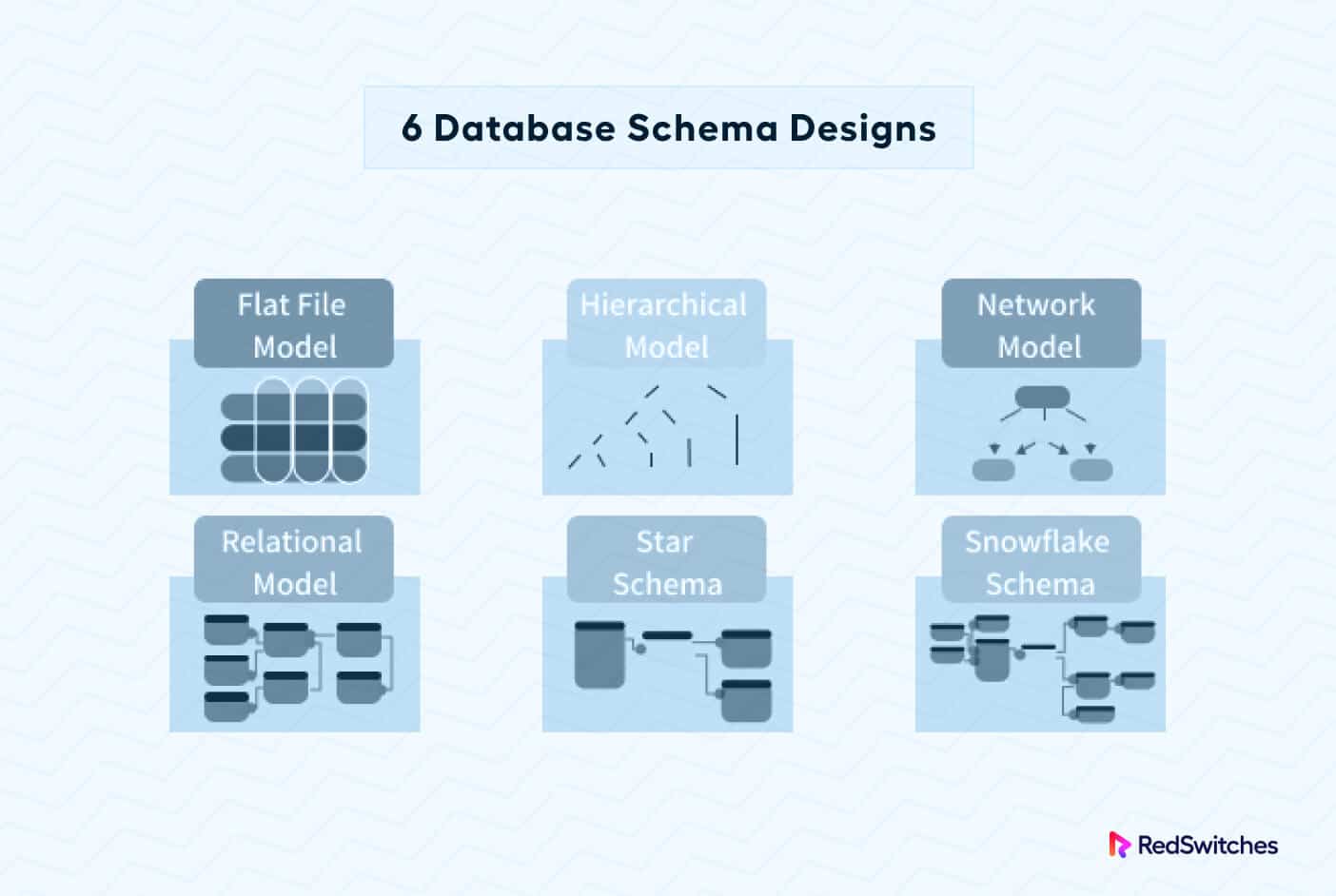
Now that you know how database schemas are classified, the next important topic is schema models. These models describe how schemas are implemented to match database capabilities with operational requirements.
Database schemas can be broadly categorized into the following six types.
Flat Model
The flat model represents the simplest form of database schema design.
Data is stored in a single table without explicit relationships or structure, resembling a flat file where information is stored sequentially. This model is commonly used for small-scale applications with limited data requirements.
Example
A flat model database schema for a customer management system might consist of a single ” Customers ” table with columns for customer ID, name, address, and contact details. Each row in the table represents a distinct customer record.
Hierarchical Model
The hierarchical model organizes data in a hierarchical tree-like structure, where each record (except the root record) has a single parent record. Parent-child relationships are established between records, enabling one-to-many relationships. The hierarchical model is suitable for representing data with natural hierarchical relationships.
Example
An employee management system is an excellent example of a hierarchical model. The database schema may include an “Employees” table where each row represents an employee and includes an employee ID column. A separate “Managers” table could have a manager ID column, establishing a hierarchical relationship between employees and their respective managers.
Network Model
The network model expands upon the hierarchical model by allowing records to have multiple parent records. It introduces the concept of pointers, which establish connections and define relationships between records. The network model excels at representing complex relationships and many-to-many relationships.
Example
The database schema might have a “Books” table and an “Authors” table in a library management system. Each book record in the “Books” table can be associated with multiple author records, creating a network of relationships. Pointers are utilized to establish connections between books and their respective authors.
Relational Model
The relational model is the most widely adopted and popular database schema design. It organizes data into tables, with relationships between tables defined by primary and foreign keys. The relational model offers flexibility, data integrity, and robust support for complex queries and joins.
Example
A typical example of the relational model is a student information system. The database schema would include tables such as “Students,” “Courses,” and “Enrollments.” The “Students” table stores student information, the “Courses” table holds course details, and the “Enrollments” table establishes a many-to-many relationship between students and courses using primary and foreign keys.
Star Schema
The star schema is a multi-dimensional model commonly employed in data warehouses to facilitate advanced analytics.
It consists of a central fact table linked to multiple-dimensional tables. While the star schema is user-friendly, it can be space-intensive due to the lack of sub-dimensional table links, which may restrict data scalability.
Example
Let’s explore a sales analysis system as an example of a star schema. The central focus is the fact table called “Sales,” which contains columns such as “Date,” “Product ID,” “Store ID,” and “Quantity Sold.” These columns hold quantitative measures or metrics related to sales.
Multiple dimension tables connect to the central fact table. These could be “Products” (with attributes like “Product ID,” “Product Name,” and “Category”), “Stores” (with attributes like “Store ID,” “Store Name,” and “Location”), and “Dates” (with attributes like “Date,” “Day of the Week,” “Month,” and “Year”).
These dimension tables provide additional descriptive information about the measures in the fact table, enabling analysis and reporting at different levels of granularity.
Snowflake Schema
Like the star schema, the snowflake schema is a multi-dimensional model employed in data warehouses to facilitate advanced analytics. While both schemas revolve around a central fact table, the snowflake schema connects dimensional tables to sub-dimensional tables. This enables a more normalized structure, reducing data duplication compared to an equivalent star schema.
Example
Let’s use the same sales analysis system to consider the snowflake schema. In this case, the “Products” dimension table is further normalized into sub-dimension tables like “Product Categories,” “Product Subcategories,” and “Product Details.” Each sub-dimension table contains specific attributes related to its level of granularity. For instance, the “Product Categories” table includes attributes such as “Category ID” and “Category Name,” while the “Product Subcategories” table contains attributes like “Subcategory ID” and “Subcategory Name.”
This normalization reduces data redundancy and improves data integrity by avoiding duplications. However, compared to the star schema, it introduces additional query joins, which may impact query performance.
Benefits of Database Schemas
Organizations can streamline their data management processes by leveraging a well-designed database schema.
The schema ensures effective data organization and structuring, maintains data integrity and consistency through constraints, and simplifies tasks such as querying and maintaining the database. These benefits contribute to a more efficient and reliable database system, enabling better decision-making, data analysis, and application development.
Let’s do a deeper dive into the benefits of these database schemas.
Effective Organization and Structuring of Data
A well-designed database schema is vital in effectively organizing and structuring data. It establishes a structured framework by defining tables, relationships, and constraints. This allows data to be logically categorized and establishes connections between entities.
With an explicit schema, data can be efficiently organized, grouped, and accessed based on its purpose and relevance. Effective data organization simplifies data management, improves retrieval speed, and enhances overall database performance.
Ensure Data Integrity and Consistency
Database schema constraints are instrumental in maintaining data integrity and consistency.
Constraints, such as primary keys, unique keys, foreign keys, and check constraints, enforce rules and restrictions on data stored in the database. They prevent the insertion or modification of invalid or inconsistent data. By defining these constraints within the schema, designers can introduce data integrity to ensure that the database remains accurate, reliable, and free from anomalies. The schema acts as a safeguard to preserve data quality and reliability.
Simple Database Management and Maintenance
A well-defined and structured schema simplifies managing and maintaining a database. It provides a clear and standardized way to query the database, making data retrieval straightforward.
The schema enables users to understand the database structure easily, facilitating efficient updates, modifications, and additions to the data.
Additionally, the schema serves as a valuable reference for documentation, offering insights into the database’s organization, relationships, and supported business rules. This documentation is invaluable in troubleshooting, debugging, and overall database maintenance.
The Process of Creating a Database Schema
Creating a database schema necessitates a thoughtful approach, starting with planning and design, then identifying entities, attributes, and relationships. The final step involves implementing the schema using SQL or database management tools.
Let’s discuss these essential aspects of creating a database schema.
Planning and Designing the Schema
The process of creating a database schema begins with meticulous planning and design. At this point, the database designers start by comprehending the system requirements and determining the objectives and goals of the database.
During this phase, the schema designer conceptualizes the structure and layout of the database, taking into account factors such as data types, relationships, and constraints.
The time invested in adequate planning sets the groundwork for a well-organized and efficient database schema.
Identifying Entities, Attributes, and Relationships
Upon completing the planning phase, the next step is identifying and defining the system’s entities, attributes, and relationships.
Entities represent real-world objects or concepts that the database will store information about, while attributes describe the properties or characteristics of these entities. Relationships establish associations between entities, specifying how they interact or relate to each other.
Accurately identifying these elements is crucial for precisely defining the structure and content of the database schema.
Implementing the Schema Using SQL or Database Management Tools
Once the entities, attributes, and relationships have been identified, the database schema is implemented using SQL (Structured Query Language) or database management tools.
In SQL, the schema is created by employing statements like CREATE TABLE, which define the tables and their columns, data types, and constraints. Alternatively, visual database design tools offer a graphical interface for designing and generating the schema, making it easier to visualize and manipulate the database structure.
Implementation involves creating the necessary tables, establishing primary and foreign keys, defining relationships, and applying constraints to ensure data integrity.
The Steps Required To Create Database Schema
After that brief overview of the database schema creation process, let’s go into more detail with a step-by-step discussion of the significant process milestones.
Define Tables and Their Columns
The initial step in creating a database schema is to define the tables and their respective columns. Tables represent the entities within the database, while columns specify the attributes or properties of those entities.
During this phase, you assign names to the tables and their columns, select appropriate data types for each column (integer, string, or date), and establish constraints, such as data length restrictions or mandatory field requirements.
Specify Data Types and Constraints
In this step, you specify the data types for each table column.
Common data types include integers, strings, dates, and floating-point numbers. Furthermore, you enforce constraints to ensure data integrity. For instance, you can define primary keys to guarantee uniqueness and enforce referential integrity between tables. In addition, you can consider additional constraints, such as uniqueness or check constraints, to further ensure data consistency and accuracy.
Establish Relationships and Foreign Key Constraints
You establish relationships between tables during this stage and enforce referential integrity using foreign key constraints.
Relationships determine the connections between tables, such as one-to-one, one-to-many, or many-to-many relationships. By defining foreign keys within the tables, you establish links between the primary key of one table and the corresponding column in another table. This ensures that the referenced data exists and maintains consistency across tables.
Indexing and Optimizing the Schema for Performance
You can create indexes on the columns within the schema to enhance query performance. Indexes facilitate rapid access to specific data, accelerating search, filtering, and sorting operations. By identifying frequently accessed columns or columns utilized in joins, you can create suitable indexes to optimize query performance. Additionally, analyzing query patterns allows schema design optimization through denormalization or partitioning of tables to improve overall performance.
Best Practices for Database Schema Design
Now that you know how to create a database schema, it’s essential to list down the best practices for database schema design. Some of the best practices are well known, but the following list will include comprehensive ideas you must remember when planning the database schema.
Best Practice No 1:Normalization Techniques
Normalization is fundamental to designing a database schema that reduces data redundancy and improves data integrity.
The idea involves organizing data into multiple related tables (each serving a specific purpose) to eliminate unnecessary duplication of information. There are three levels of normalization, namely 1NF, 2NF, and 3NF, which provide guidelines for achieving an optimal database structure.
First Normal Form (1NF)
In 1NF, data is organized into tables where each column holds atomic values (indivisible values). It ensures no repeating groups, and each row is unique. By eliminating duplicate data, 1NF ensures the reliability of the database.
Second Normal Form (2NF)
2NF builds upon 1NF by addressing partial dependencies.
A table is in 2NF if it is in 1NF and doesn’t contain any columns that depend on only a portion of the primary key. This involves identifying and separating data that depends on only part of the primary key into separate tables.
Third Normal Form (3NF)
3NF further refines normalization by handling transitive dependencies. A table is in 3NF if it is in 2NF and contains no columns that depend on non-key attributes. Any non-key attribute should depend solely on the primary key, not other non-key attributes.
Applying these normalization techniques helps eliminate redundancy, improve data consistency, and simplify database maintenance.
Best Practice No 2:Consistency and Naming Conventions
Consistency in schema design is vital for creating a coherent and maintainable database. Here are some best practices to maintain consistency and adopt meaningful naming conventions:
Standardize Naming Conventions
Establish consistent naming conventions for tables, columns, constraints, and other database objects. Use descriptive names that accurately represent the stored data or relationships. Avoid ambiguous or cryptic abbreviations.
Be Descriptive and Concise
Choose names that convey the purpose and meaning of the objects they represent. Avoid excessively long names that can be cumbersome to work with. It’s essential to strike a balance between being descriptive and concise.
Use Camel Case or Underscores
Select a consistent naming style, such as camel case (e.g., firstName) or underscores (e.g., first_name), and apply it uniformly throughout the schema. This improves readability and makes distinguishing between words in object names easier.
Follow a Logical Naming Hierarchy
Organize tables and related objects in a logical hierarchy that reflects their relationships and dependencies. For example, use prefixes or namespaces to group related tables.
Avoid Reserved Words and Special Characters
Ensure that object names do not conflict with reserved words and avoid using special characters that may cause issues with query execution or compatibility across different database management systems.
Best Practice No 3:Don’t Forget To Document the Schema for Future Reference.
Documentation is crucial in understanding, maintaining, and evolving a database schema. Here’s why documenting the schema structure, relationships, and constraints is significant:
Improved Understanding
Documenting the schema provides a comprehensive overview of the database structure, making it easier for developers, administrators, and other stakeholders to understand how data is organized, the relationships between tables, and the purpose of each object.
Efficient Maintenance and Troubleshooting
Well-documented schemas assist in troubleshooting and resolving issues more efficiently. They help developers and administrators identify potential problem areas, understand dependencies, and make informed decisions when modifying the schema.
Facilitates Collaboration
Documentation promotes effective collaboration among team members by providing a shared reference point. It enables developers to work together, understand each other’s changes, and maintain consistency across the schema.
Future Scalability and Evolution
As the database evolves, documented schema information becomes crucial for planning and implementing changes. Designers can better evaluate the impact of modifications on existing functionality and develop with more efficient upgrades or migrations.
When documenting the schema, consider including table and column descriptions, relationships and foreign key constraints, primary key and unique vital definitions, indexes and their purpose, data types and constraints, and any stored procedures, functions, or triggers associated with the schema.
We recommend using documentation tools like entity-relationship diagrams (ERDs), data dictionaries, or schema documentation generators to automate and assist in generating schema documentation.
Steps in Database Schema Evolution and Maintenance
Many database schema designers don’t consider the question of database schema maintenance. Many designers and administrators think of database schema maintenance when the data integrity gets compromised.
Maintaining the database schema is as important as designing. Therefore, paying close attention to the steps involved in maintaining database schema is essential. Let’s discuss the steps in detail:
Step No 1:Modify and Update the Schema
When the requirements of a database system evolve, it becomes necessary to modify and update the existing schema.
This process requires careful planning and effective management to maintain data integrity and minimize disruptions.
Analyze and Plan the Changes
Begin by analyzing the desired changes and understanding their impact on the existing schema. Identify the tables, columns, relationships, and constraints that need modification, addition, or removal. Evaluate the potential risks and benefits associated with the changes.
Develop a Migration Strategy
Based on the analysis, create a migration strategy to implement the changes. Consider factors such as the order of operations, data backup and migration, and any required downtime or maintenance windows. Plan for contingencies and define rollback options in case unforeseen issues arise.
Execute the Schema Modifications
Implement the planned changes by executing the necessary SQL statements or running the schema management tools. This may involve adding or modifying tables, altering columns, creating or dropping constraints, and updating data. Follow the defined migration strategy to ensure accurate and efficient implementation of the changes.
Test and Validate
Thoroughly test the modified schema and associated applications to ensure proper functionality with the new changes. Validate data integrity, perform regression testing, and verify that all queries and processes continue to work as expected.
Communicate and Document
Inform all relevant stakeholders, including developers, administrators, and users, about the schema modifications and any necessary adjustments to their workflows. Update the documentation and schema diagrams to reflect the new structure accurately.
Step No 2:Handle Schema Migrations and Versioning.
Schema migrations involve the management of a database schema’s evolution over time, including versioning, change tracking, and seamless updates. Here are techniques and tools to handle schema migrations effectively:
Version Control for the Schema
Utilize a version control system, such as Git, to track and manage changes to the schema. Store SQL scripts or migration files in a version-controlled repository, enabling easy tracking and comparing schema versions. Use tags to mark releases or significant changes. This simple step sets up an easy system to identify rollback points.
Employ Migration Tools
Schema migration tools provide automated management of database changes. They assist in generating migration scripts, tracking their execution, and ensuring the proper ordering of changes. Popular examples include Flyway, Liquibase, and Django’s built-in migration framework.
Use Script-Based Migrations
We recommend creating and executing SQL scripts for each schema change. To maintain chronological order, these scripts are organized in a directory structure based on version numbers or timestamps. Apply the scripts sequentially to update the schema to the desired state.
Plan for Rollbacks and Roll-Forward
Include rollback scripts or similar mechanisms to revert schema changes in case of issues or to support the ability to return to a previous version. Additionally, ensure the ability to apply forward migrations to newer versions, if required.
Integrate With Continuous Integration and Deployment (CI/CD)
Integrate schema migrations into your CI/CD pipeline to automate the deployment of database changes alongside application code changes. This ensures consistency and synchronization between the schema and the application.
Test and Validate
Lastly, thoroughly test schema migrations before applying them in a production environment. Set up testing environments that mirror the production setup and perform end-to-end testing to validate the changes. This helps identify issues and mitigate risks during the migration process.
Conclusion
This article provides an in-depth answer to the question: what is schema in database?
The significance of a well-designed and meticulously maintained database schema cannot be overstated. It guarantees orderly data organization, preserves data integrity, enables scalability, and maximizes performance optimization.
Organizations can establish and sustain a resilient database schema by embracing best practices, including normalization, consistent naming conventions, and comprehensive documentation.
Additionally, collaborating with a reliable hosting provider like Redswitches enhances the dependability and scalability of your database infrastructure, facilitating smooth operations and empowering data-centric applications.
FAQ
Q-1) What are the various components of Database Schema?
A database schema comprises various components such as tables, columns, constraints, indexes, and views.
Q-2) Is Database schema specific to a particular database management system?
Certainly yes, a database schema is specific to the DBMS being used. Different Databases have their own rules and syntax for defining database schemas. However, the concepts of tables, columns, and constraints are common to most NOSQL database systems.
Q-3) Can a Database Schema be exported and imported from another database?
Yes, the exportation and importation of database schemas can be done using standard data interchange formats like SQL scripts or XML. This permits transferring the structure and definition of tables, columns, constraints, and relationships from one database to another.
